En estos renglones se muestra más que un decálogo de ideas con Linux, como era la idea original. Todo *NIX tiene una filosofía propia, la premisa de ser simple, pero es muy potente y amplio en sus posibilidades. De programas, preferiblemente, con un solo propósito, como ls, para listar archivos, podemos ir añadiendo complejidad mediante la combinación de comandos y el uso de elementos como tuberías, simbolizadas por |. ¿Recordáis cuando teníais un montón de piezas de Lego? Esto podía ser un castillo. Esto otro podía ser un pequeño barrio. Con Linux, sus comandos, su potencial de automatización y su posibilidad de manipular cadenas de texto ocurre algo parecido. Las posibilidades para procesar información son amplísimas.
Idea cero. ¿Cómo se visualizará este fichero Markdown usando VS Code? Ctrl + Shift + V. Y para los ejemplos aquí se utiliza Manjaro, esto puede variar empleando otra distribución Linux, así como advertencia.
La tabla más útil del orbe #
Habrán advertido que la consola de comandos funciona de una manera distinta a muchos de los programas que se usan en el día a día. Por ejemplo, con CTRL + Backspace no borrarán palabras enteras, como sí sucede mientras escribo en VS Code. Apúntese esto y deje que la memoria muscular haga el resto (extraído de Computing Skills for Biologists).
| Atajo | ¿Qué hace? |
|---|---|
| Ctrl+A | Ir al comienzo de la línea. |
| Ctrl+E | Ir al final de la línea. |
| Ctrl+L | Limpia la pantalla. |
| Ctrl+U | Borrar todo lo anterior a nuestro cursor. |
| Ctrl+K | Borrar todo lo posterior a nuestro cursor. |
| Ctrl+C | Cancelar la ejecución en curso (útil si está tomando mucho tiempo, p.e.). |
| Ctrl+D | Salir de la consola en la que estamos. |
| Alt+F | Mover el cursor una palabra para adelante (en OS X, Esc+F). |
| Alt+B | Mover el cursor una palabra para atrás (en OS X, Esc+B). |
Consultar el estado de la batería desde consola #
acpi en la CLI nos informa del estado de la batería y de cuánto queda. Una alternativa es upower -i $(upower -e | grep 'BAT') | grep -E "state|to\ full|percentage". Por último, siendo más rústicos, podemos acceder vía cat /sys/class/power_supply/BAT1/capacity.
Resolución máxima en MPV #
¿Cómo ponemos una resolución tope en el MPV, para no preocuparnos cada vez que queramos reproducir algo? En mpv.conf pondremos ytdl-format=bestvideo[height<=?1080]+bestaudio/best. ¿Dónde lo guardamos? ~/.config/mpv/. Para incorporar un historial, podemos ver este script y usarlo.
Historial del Zathura en formato HTML #
Imaginemos que tenemos una cómoda tabla en formato HTML y nos gustaría reflejarla. Quisiéramos mostrar todo lo leído en Zathura. Primero instalamos zathura-pdf-poppler para poder leer en PDF. Abrimos un documento y lo cerramos con la tecla Q. En ~/.local/share/zathura es donde hallaremos nuestra configuración. Este script Python nos servirá mucho, siempre que se nos haya ocurrido poner la configuración en texto plano. Existe la opción de usar SQLite, en este caso será más sencillo y radicará. normalmente, en ~/.local/share/zathura/bookmarks.sqlite.
1from configparser import ConfigParser
2from datetime import datetime
3import pandas as pd
4from os.path import expanduser
5
6to_load = expanduser("~/.local/share/zathura/history")
7name = to_load.split('/')[-1]
8config = ConfigParser()
9config.read(to_load)
10
11# comprobar las secciones
12sections = [i for i in config.sections() if i.startswith("/home")]
13pages = [config.get(i, "page") for i in sections] # obtener las páginas
14times = [datetime.utcfromtimestamp(int(config.get(i, "time"))).strftime('%Y-%m-%d %H:%M:%S') for i in sections]
15
16# a Pandas
17df = pd.DataFrame({'file': sections, 'page': pages, 'last_time': times})
18html_table = df.to_html(index=False)
19
20# escritura
21with open(f"{name}.html", "w") as text_file:
22 html = f"""
23 <!DOCTYPE html>
24 <html>
25 <head>
26 <title>HTML table for {name}</title>
27 <link rel="stylesheet" type="text/css" href="table.css"/>
28 </head>
29 <body>
30 {html_table}
31 </body>
32 </html>
33 """
34 text_file.write(html)
Introducir feeds RSS para YouTube #
Ante todo, será menester instalar newsboat, un lector de RSS en consola de comandos con una gran capacidad de personalización y comprobar que existe el fichero urls dentro de ~/.newsboat/. En caso contrario, se crea con touch ~/.newsboat/urls. Imaginemos que se nos ha conferido una URL y queremos extraer su ID, yt-dlp nos rescatará ahí. Con este comando tendremos la ID del canal que deseemos.
1yt-dlp --playlist-items 0 -O playlist:channel_id https://youtube.com/c/freecodecamp
La base para cualquier Feed RSS en YouTube es la siguiente, https://www.youtube.com/feeds/videos.xml?channel_id=. Sabiendo su ID, es pan comido. Un ejemplo lo tendremos con yt-dlp --no-download-archive --playlist-items 1 --print "https://www.youtube.com/feeds/videos.xml?channel_id=%(channel_id)s" https://youtube.com/c/freecodecamp. ¿Cómo integrar eso de un vistazo en Newsboat? Pongamos un vídeo de tal canal en el navegador. Nos ha gustado, queremos saber más de él.
1yt-dlp --no-download-archive --playlist-items 1 --print "https://www.youtube.com/feeds/videos.xml?channel_id=%(channel_id)s" https://www.youtube.com/watch?v=NIFEXCGTPhg >> ~/.newsboat/urls
Más ejemplos:
1# FreeCodeCamp
2yt-dlp --no-download-archive --print "https://www.youtube.com/feeds/videos.xml?channel_id=%(channel_id)s" https://www.youtube.com/watch?v=RZ4p-saaQkc >> ~/.newsboat/urls
Y así es como uno ya está suscrito.
Y seguimos. Otro ejemplo de cómo extraer la ID sería con yt-dlp --print channel_url --playlist-items 1 https://www.youtube.com/user/pewdiepie.
Descarga y descomprime #
Con estos sencillos comandos adosamos la URL deseada con nuestro ZIP a una variable, luego creamos un archivo temporal, lo descomprimimos y por último lo eliminamos.
1$ZIP="https://www.datascienceatthecommandline.com/2e/data.zip"
2wget $ZIP -O temp.zip && unzip $_ && rm $_
Ejemplo con cURL #
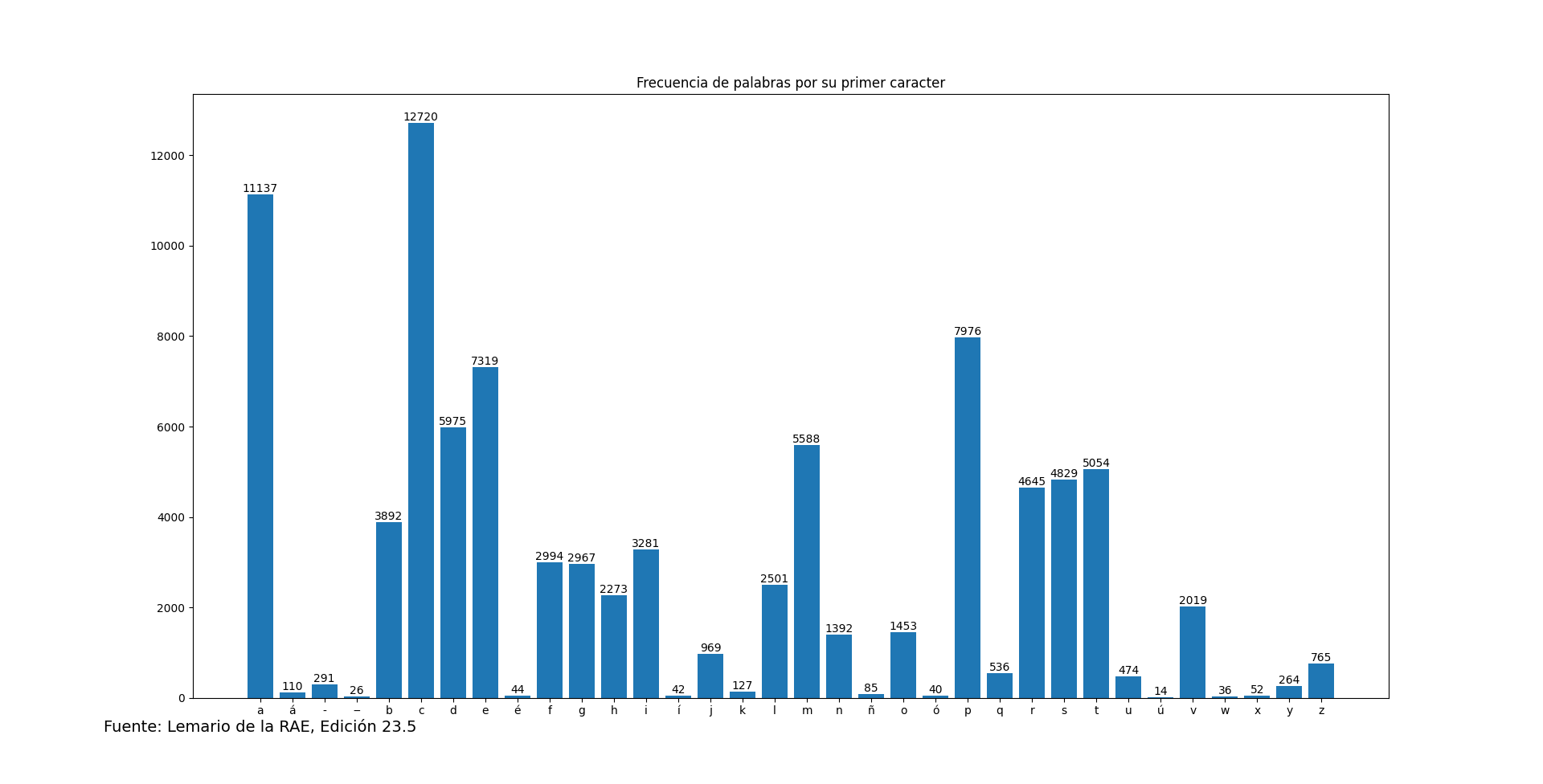
¿Cuántas palabras tenemos en el lemario que Iedra nos ha facilitado? Utilizaremos el modo silencioso en cURL para que no nos salga contenido. ¿Cuántas palabras hay? Con una sencilla tubería, lo tenemos hecho. Y así sea: curl -s "https://iedra.es/static/lemario-23.5.txt"| wc -l. ¿Cuál es la distribución por letras? Python nos resuelve la duda.
1import urllib
2from collections import Counter
3import matplotlib.pyplot as plt
4
5lemario = urllib.request.urlopen("https://iedra.es/static/lemario-23.5.txt").read().decode("utf-8")
6lista = lemario.split("\n")[:-1] # sabemos que hay una línea vacía final
7lista = [lema.lower() for lema in lista] # armonizamos todo el lemario
8contador = Counter(lema[0] for lema in lista) # contamos por alfabeto
9
10# gráficos
11names, counts = zip(*contador.items())
12plt.bar(names, counts)
13ax = plt.gca()
14plt.bar_label(ax.containers[0])
15ax.set_title('Frecuencia de palabras por su primer caracter')
16plt.annotate('Fuente: Lemario de la RAE, Edición 23.5', (0,0), (-80,-20), fontsize=14,
17 xycoords='axes fraction', textcoords='offset points', va='top')
18plt.show()
Tenemos, entonces, nuestra respuesta.
Regex cotidianas #
Una considerable parte de los datos con los que trataremos en un ordenador serán cadenas de texto. Normalmente las consumiremos en forma de lecturas recreativas, ¿pero y si hay que trabajar con texto? Las expresiones regulares nunca están de más. Nos pasan, verbigracia, una lista de palabras sueltas separadas por un espacio. Cualquier editor de texto que se precie, como Notepad++ o Mousepad, donde buscar y reemplazar, tiene capacidad para reconocer expresiones regulares. Con (\w+) señalaremos las palabras. Con (\s+) los espacios. Con (\d+) los dígitos y así sucesivamente. Conozcan los comodines, caballeros.
-
¿Que has creado un rango de fechas en Python? Copiamos
list(range(1900, datetime.today().year))a nuestro editor de texto. Detectaremos que habrá un espacio por delante en cada nueva línea, así que lo marcaremos con esta expresión regular,\s(\d{4}). La reemplazaremos por\1, conservando los años. Las parentésis sirven para marcar el grupo. -
Nos dan una lista de nombres en texto plano. Necesitamos convertirla de un solo golpe en Python. Tenemos los 2' nombres más frecuentes para los hombres del INE:
ANTONIO
MANUEL
JOSE
FRANCISCO
DAVID
JUAN
JAVIER
JOSE ANTONIO
DANIEL
FRANCISCO JAVIER
JOSE LUIS
CARLOS
JESUS
ALEJANDRO
MIGUEL
JOSE MANUEL
RAFAEL
MIGUEL ANGEL
PABLO
PEDRO
Los nombres compuestos ya complican el análisis, pero no nos amilanaremos. Cojan su editor de texto favorito, en este caso Mousepad, y elaboren la regex. Detectaremos los nombres, sean compuestos o no, con ^(\w+(?: \w+)?). Lo reemplazamos por '\1',. Encerramos entre comillas el grupo de captura de interés. Agregamos a mano los corchetes y ya tendremos una lista en Python:
['ANTONIO',
'MANUEL',
'JOSE',
'FRANCISCO',
'DAVID',
'JUAN',
'JAVIER',
'JOSE ANTONIO',
'DANIEL',
'FRANCISCO JAVIER',
'JOSE LUIS',
'CARLOS',
'JESUS',
'ALEJANDRO',
'MIGUEL',
'JOSE MANUEL',
'RAFAEL',
'MIGUEL ANGEL',
'PABLO',
'PEDRO']
Conocer los MIME Types #
Deleítate con /usr/share/applications/mimeinfo.cache, eso sí, para meter mano hace falta ya ser administrador. Es, sencillamente, qué programas están asociados a tal formato. Por ejemplo, ¿qué programa abren los ficheros HTML? Y con punto y coma separamos los programas según su orden de prioridad, como es este caso, image/x-xbitmap=gimp.desktop;viewnior.desktop;. Siendo texto plano, manipular es sencillo. Por ejemplo, imaginemos que lo queremos en un dataframe en Pandas. Coser y cantar:
1import pandas as pd
2pd.read_csv("/usr/share/applications/mimeinfo.cache", sep="=", skiprows=1, names=["Extension", "Application"])
Luego lo exportaremos a Markdown (¡necesitaremos el paquete tabulate!), HTML, CSV o lo que nos dé la gana. Lo podemos ver, por ejemplo, así (muestra de 10):
| Extension | Application |
|---|---|
| image/pdf | qpdfview.desktop; |
| audio/vnd.dts | mpv.desktop; |
| application/vnd.debian.binary-package | engrampa.desktop; |
| text/csv | org.onlyoffice.desktopeditors.desktop; |
| application/csv | org.onlyoffice.desktopeditors.desktop; |
| application/x-ogm-audio | mpv.desktop; |
| audio/vnd.dts.hd | mpv.desktop; |
| application/x-sqlite2 | sqlitebrowser.desktop; |
| text/x-pdf | qpdfview.desktop; |
| video/x-mpeg3 | mpv.desktop; |
SCRAPE FROM BASH! #
Me gusta usar scraping, más en estas empresas, así que pongámonos manos a la obra. Primero instalamos pup, una herramienta útil para extraer información de una página web en concreto cuando estamos trabajando en consola de comandos, en consonancia con curl, como en ese ejemplo, donde incorporaremos nuestra cara referencia a un fichero de bibliografía que luego podemos utilizar en algún escrito o abrirlo con Jabref:
1curl -s http://libgen.st/book/bibtex.php?md5=BD698A2185AC1F51752FDFD446CF14EF | pup '#bibtext text{}' >> libgen.bib
Con esto extraemos el texto que hay dentro del textarea. ¡Coser y cantar! Incluso se puede usar sed para meter un cambio y así tener una referencia única.
curl -s http://libgen.st/book/bibtex.php?md5=BD698A2185AC1F51752FDFD446CF14EF | pup '#bibtext text{}' | sed "s/book:{[0-9]\+}/book_$RANDOM/g" >> libgen.bib
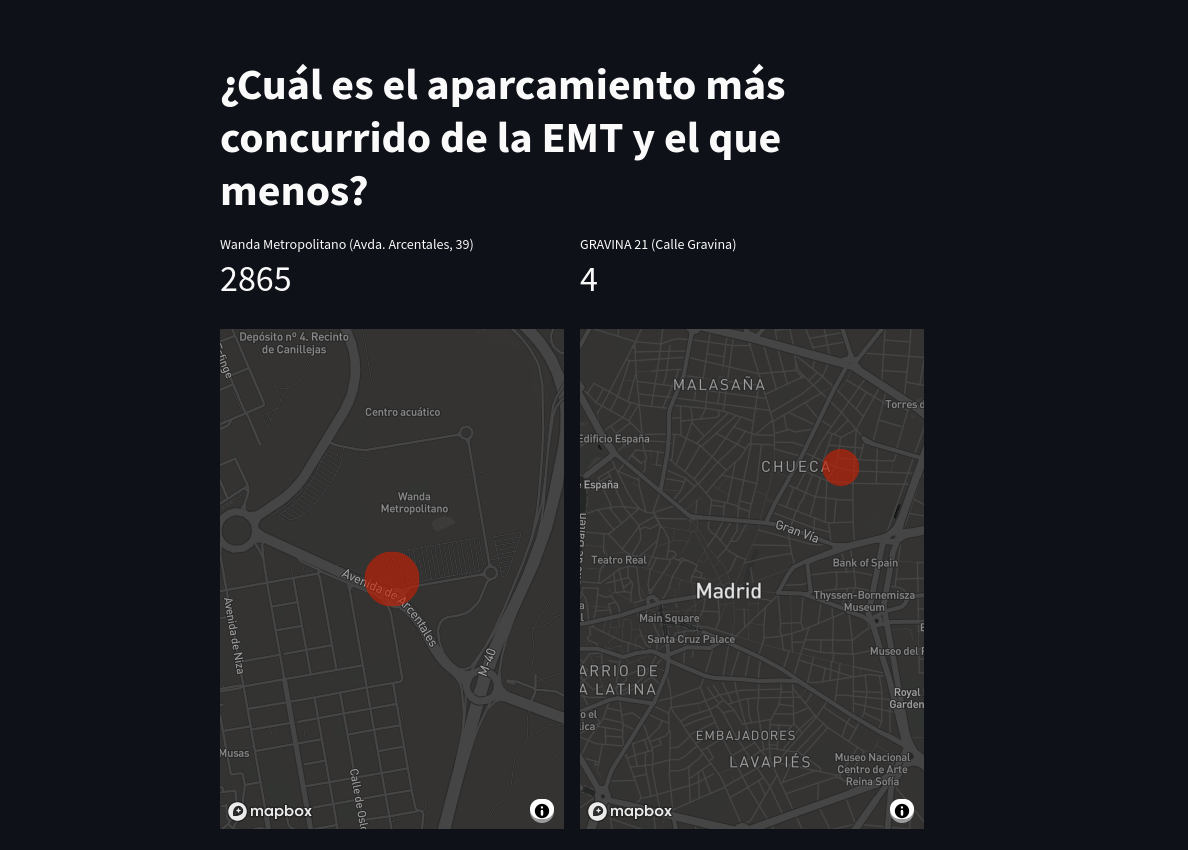
El botón mágico para pedir el aparcamiento más concurrido en Madrid #
La empresa municipal de transportes nos ofrece una API con la que podremos ver cuántas bicicletas públicas hay disponibles en tal punto, cuánto tardará el próximo autobús o los puntos de interés en Madrid. Esta vez nos interesa saber cuál es el aparcamiento más concurrido en Madrid y el que menos de un solo golpe. Hay código y capas de abstracción detrás, así que agarraos. Vamos a montar un dashboard sencillo en Streamlit. Tengan el código completo. ¡Y con la tecla R correremos los datos de nuevo!
1import streamlit as st
2import requests
3import pandas as pd
4
5# Conexión a la API
6@st.experimental_memo
7def token(uri):
8 headers = {'X-ApiKey': st.secrets['api_key'], 'X-ClientId': st.secrets['client_id'], 'passKey': st.secrets['passkey']}
9 r = requests.get(uri, headers = headers)
10 token = r.json()['data'][0]['accessToken']
11 return token
12
13# Información
14token = token("https://openapi.emtmadrid.es/v2/mobilitylabs/user/login/")
15aparcamientos = requests.get("https://openapi.emtmadrid.es/v2/citymad/places/parkings/availability/", headers = {"accessToken": token})
16emt = pd.DataFrame.from_dict(aparcamientos.json()['data'])
17aparcadero_max, aparcadero_min = (emt.loc[emt['freeParking'].idxmax()], emt.loc[emt['freeParking'].idxmin()])
18
19st.title('¿Cuál es el aparcamiento más concurrido de la EMT y el que menos?')
20col1, col2 = st.columns(2)
21
22with col1:
23 st.metric(label=f"{aparcadero_max['name']} ({aparcadero_max['address']})", value=int(aparcadero_max['freeParking']))
24 st.map(pd.DataFrame.from_dict({"lat": [aparcadero_max['geometry']['coordinates'][1]], "lon": [aparcadero_max['geometry']['coordinates'][0]]}), zoom=14)
25
26with col2:
27 st.metric(label=f"{aparcadero_min['name']} ({aparcadero_min['address']})" , value=int(aparcadero_min['freeParking']))
28 st.map(pd.DataFrame.from_dict({"lat": [aparcadero_min['geometry']['coordinates'][1]], "lon": [aparcadero_min['geometry']['coordinates'][0]]}), zoom=14)
29
30st.dataframe(emt)
Nótese que hemos traído las credenciales del fichero secrets.toml, en la carpeta .streamlit dentro de nuestro proyecto. Es una práctica de seguridad recomendada para evitar difundir datos confidenciales a la hora de compartir código. Como hayamos obrado bien, se verá así:
Por último, más consejos... #
- Di con un comentario curioso en algún sitio. Enlazaré muchos de los paquetes para el interesado, y comentaré brevemente sobre algunos de ellos.
I always install these pkgs: stow git curl rsync tldr hors alacritty fzf tree fd rg bat keepassxc liferea yt-dlp mpv thunar tumbler gvfs-smb neovim trans
fd: búsquedas muy rápidas en Linux, ver https://www.linuxadictos.com/fd-un-simple-comando-para-realizar-busquedas-muy-rapidas.html
hors: consejos de código, ver más en https://github.com/WindSoilder/hors
alacritty, emulador de terminal.
De mpv y yt-dlp, qué decir. Uno es el mejor reproductor de vídeo que hay y el otro, lo mejor que hay para descargar vídeos de cientos de sitios. Cuando ambos se combinan, es aún más maravilloso. Lo que tienen los usuarios de Youtube Premium en tu casa. Ver a Félix Rodríguez de la Fuente en serenidad. Incluso hemos hablado de ambos programas un pelín en estas líneas y un día vamos a escribir en profundidad al respecto.
fzf, fuzzy search o búsqueda por criterios probabilísticos. Útil para ver, verbigracia, qué archivos se acercan más en sus nomenclaturas al término con el que estamos buscando. Sirve para cualquier lista que tengamos, como nuestro historial de comandos.
tldr nos ofrece ejemplos prácticos de casos de uso de nuestros programas en consola de comandos, como para qué sirve ls -lah. Perfecto para ir al grano y no perder el tiempo en la documentación que nos escupa el comando man.
bat es una alternativa al manido comando cat y más completa. Por ejemplo, los ficheros CSV los mostrará como los cánones mandan, con tablas.
rg o ripgrep, una evolución de grep, para ver por qué es más rápido que grep.
trans es para traducir textos en consola de comandos, ejemplos de uso.
rsync, manual práctico en https://www.proxadmin.es/blog/rsync-10-ejemplos-practicos-de-comandos-rsync/
¡Hay más! En esta otra lista predominan los programas de Suckless.
dwm, sxhkd, slstatus, st, nsxiv, nvim, dmenu, vifm, vscodium, mpv, mpd, ncmpcpp, feh, urxvt, ueberzug, gcolor2, zsh, maim, picom-jonaberg, dunst, librewolf, tor-browser.
Ahora, bien, un análisis de conjuntos.
1a = {'stow','git','curl','rsync','tldr','hors','alacritty','fzf','tree','fd','rg','bat','keepassxc','liferea','yt-dlp','mpv','thunar','tumbler','gvfs-smb','neovim','trans'}
2b = {'dwm', 'sxhkd', 'slstatus', 'st', 'nsxiv', 'nvim', 'dmenu', 'vifm', 'vscodium', 'mpv', 'mpd', 'ncmpcpp', 'feh', 'urxvt', 'ueberzug', 'gcolor2', 'zsh', 'maim', 'picom-jonaberg', 'dunst', 'librewolf', 'tor-browser'}
3
4a.intersection(b)
Sólo mpv coincide. Aunque también se podría comentar el caso de NeoVim, presente en ambos conjuntos, sólo que bajo distintos comandos.
-
gcolor2está instalado por defecto en Manjaro. Si uno trabaja con webs o maquetación, muy útil para extraer colores que inspiren. -
maimes utilísimo para capturar imágenes en tu PC de manera sencilla. -
docker run -p 8888:8888 [container]es útil para correr contenedores estilo cuadernos Jupyter que requieran de puertos. -
Piratea con
pirate-get, que te enseñará una sencilla lista de pinículas conpirate-get commando 1985, e.g. Peerflix lleva una pechá de tiempo sin actualizarse, habría que comprobar cómo está. Al elegir un enlace con pirate-get, se abre rápidamente tu cliente Torrent (en mi caso, Deluge). Otra posible alternativa sería Kickflix, pero soy escéptico con WebTorrent, ya que tira de RAM y en ordenadores que vayan algo justos puede ser una catástrofe. -
Usa
trpara reemplazar rápidamente según qué cosas, comoecho "Hola, 5FIVER" | tr 'A-Z' 'a-z', que lo pone todo en minúsculas. O resumir repes en una letra,echo "aaaaaabbbbb" | tr -s ab -
RSS Bridge puede ser un incordio, implica tener PHP instalado, ¿pero y si pudieras convertir una cuenta de Twitter en RSS vía otro medio? ¡Nitter! Ejemplo: https://nitter.net/rcafdm/rss
-
¡Cuenta fácilmente las pestañas en cualquier navegador basado en Chromium, como Brave o Vivaldi! Aviso, no se actualiza en directo, así que habría que cargar cada vez que se cerrase una o varias pestañas. En cambio, sí que lo hace en cuanto se abre una pestaña o varias.
-
Abre tu webcam en MPV,
mpv --profile=low-latency -untimed /dev/video2en mi caso para la cámara en USB. Para ver qué dispositivo escoger,v4l2-ctl --list-devices.